6월 한 달 간 진행했던
AI 막차 탑승 : HyperCLOVA X 프로젝트 챌린지!
0. 챌린지 참가 이유
크게 두 가지로 나누어 볼 수 있을 것 같다.
A. 운영진으로 계시는 팀 내 멘토님(스승님)이 추천하셔서
B. 1년 전 하이퍼클로바가 주제였던 졸프를 발판삼아 하이퍼클로바 X를 사용해보고 싶어서
사실 B. HCX를 체험해 보고 싶은게 더 컸다. 졸프를 끝냄과 동시에 HCX 가 출시됐어서 더 좋은 모델을 쓰지 못해 아쉬웠고,
이후 1년 간 GenAI 가 무서운 속도로 발전했기 때문에 그 간극을 느껴보고 싶었다.
[GPT 예제] 네이버 GPT 모델 하이퍼클로바를 이용해서 동화창작 서비스 만들기
졸업프로젝트 마감일이 일주일 반 정도 남은 상태...1년간의 여정이 끝나간다는게 아직 안믿긴다. 졸프를 끝내고있는 나의 상황이 어리벙벙할 따름 두번째 학기인 그로쓰에는 열심히 개발과 QA
seeunhi.tistory.com
(졸프 포스팅)
그리고 거의 ChatGPT 만 사용하던 나였는데, 이 기회에 HCX도 일상에 적용해보고 싶은 기대도 있었고.
1. 챌린지 진행 방식
팀 당 4~5명이 배정되었고, 주별 자체적인 스터디를 진행했다. 마지막 주에는 간단한 개발과 산출물을 제작했다.
1주차 :
OT
주제 아이디어 탐색
2주차 :
프롬프트 엔지니어링 방식 스터디
Clova Studio 테스트앱 발행
3주차 : 튜닝
4주차 : 개발
우리 팀은 데이터 분석가, IT 개발자, 클라우드 엔지니어(나) 로 이루어졌다.다들 1인분 이상 몫을 했고 끝까지 완주해주셔서 너무나도 감사... 재미있었다.
2. 주제
맞춤형 AI 광고 카피라이터
streamlit_app (koyeb.app)
주제는 데이터마케팅 분야 종사자이신 팀원 분의 도움을 받아 선정했다.
A. 기능
- Input :
1. 산업군
2. 브랜드 명
3. 카피 스타일
- Output :
카피라이팅 결과
<첫 화면>

<결과 화면>
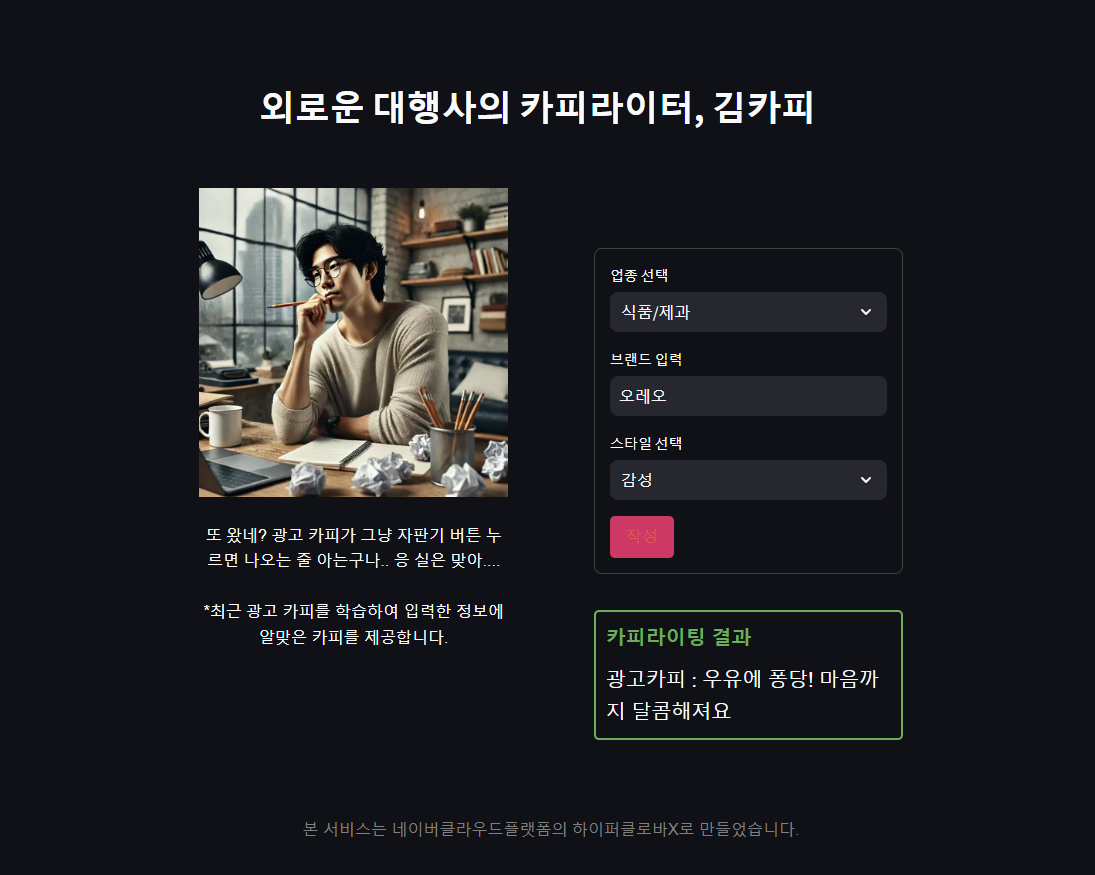
Input 세부 Option
1. 산업군
"관공서/단체", "기업PR", "생활/가정용품", "서비스/유통/레저", "식품/제과", "자동차/정유", "전기전자", "정보통신", "출판/교육/문화", "패션/스포츠", "화장품"
2. 카피 스타일
"감성", "기능", "사운드", "선언", "선점", "언어유희","영어"
B. 타 서비스와의 차별점
: 광고 카피의 '스타일'을 정할 수 있다는 것
C. 결과 예시
배포된 웹사이트에서 실제로 사용자들이 결과로 받아본 값이다.
| Input | 카피라이팅 결과 |
| 분류: 출판/교육/문화 브랜드: 가벼운학습지 스타일: 선점 |
한 주에 한 권, 세상에서 가장 쉬운 외국어 학습 |
| 분류: 식품/제과 브랜드: 포지타노 스타일: 감성 |
새콤달콤 이탈리아맛 그대로! 나폴리 정통 레몬사탕 |
| 분류: 패션/스포츠 브랜드: 탑텐 스타일: 선점 |
일상부터 야외활동까지 누구보다 TOP OF THE TEN |
3. 구현
A. Clova Studio
클로바 스튜디오 플레이그라운드에서는 다양한 프롬프트를 작성해보고 HCX 와 턴을 반복하면서 테스트 해볼 수 있다.
X 에서는 '챗 모드' 가 새로 생겨 챗지피티처럼 턴을 주고받으며 테스트 해볼 수 있어서 간편했다.
< 카피라이팅 문구를 위한 프롬프트 구성 >
- 지시문
- 예시
- 사용자 입력
당신은 수년간의 경험을 가진 전문 광고 카피라이터입니다. 3가지 항목을 사용자 입력으로 받아 창의적이고 매력적인 광고 문구를 작성해주세요.
광고 카피를 생성할 때 다음 내용을 반영하세요.
1. 브랜드의 톤앤매너를 반영할 것
2. 핵심 메시지를 효과적으로 전달할 것
3. 간결하면서도 임팩트 있는 표현을 사용할 것
4. 광고 문구에 브랜드명을 포함할 것
3가지 사용자 입력은 다음과 같습니다.
1. 분류: 브랜드의 업종 분류
2. 브랜드: 브랜드 이름
3. 스타일: 광고 문구의 스타일
스타일은 다음을 의미합니다.
- 선점 : 다른 브랜드 대비 선점
- 기능 : 제품의 기능을 강조
- 감성 : 제품의 감성적인 터치를 강조
- 사운드 : 사운드 효과 강조
- 언어유희 : 동음이의어 등 언어 유희 이용
- 영어: 영어를 이용
###
분류: 화장품
브랜드: 이니스프리
스타일: 감성
광고카피: 나의 제주 이야기가 스며든 피부, 이니스프리
###
분류: 식품/제과
브랜드: 코카콜라
스타일: 언어유희
광고카피: 코카콜라와 함께 무한탄산 무한텐션
###
분류: 정보통신
브랜드: G마켓
스타일: 선점
광고카피: 지상 최대의 선물마켓, G마켓
###
분류: 전기전자
브랜드: 애플 아이폰
스타일: 영어
광고카피: Your New Superpower
###
- '카피라이터' 라는 페르소나 지정
- 명확하게 요구사항을 정의
- Stop Sequence (###) 로 구분
- 다양한 조합의 예시를 구성
> 참고로 클로바스튜디오에 샘플로 있는 '뮤직 마케팅 문구 생성' 의 프롬프트는 다음과 같다.

B. 튜닝
B-1️⃣. 데이터셋 준비
Q. 최적화를 위한 추가학습에 쓰일 데이터에서 가장 중요한 것은?
A. 퀄리티
양보다 질이라는 말이다.
LLM 에 비해 적은 양의 데이터로 학습하는 것이기 때문에, 기존에 넣을 데이터의 적합성이 중요하다.
다행히 @copy_pedia 라는 인스타 계정에서 최신 카피라이팅 모음을 엑셀 파일로 올려주고 있어서,
쉽게 데이터셋을 구성할 수 있었다.


데이터 크기 : 1000행
----------------------------
- C_ID : Conversation ID. 동일한 주제로 구성된 대화 시나리오에 부여하는 숫자. 0~999.
- T_ID : Turn ID. 하나의 대화 시나리오 내에서 수행되는 질문(Text), 답변(Completion) 쌍에 부여하는 숫자. 0부터 시작하여 1씩 증가. 본 프로젝트에서는 모두 Single Turn 이기 때문에 전부 0.
- Text : 사용자가 말할 것으로 기대되는 모든 발화 내용
- Completion : CLOVA Studio가 답해야 할 것 으로 기대되는 모든 발화 내용
B-2️⃣. 주의할 점- HCX 튜닝생성 API 활용
💥업로드 데이터셋 규격 : UTF-8 (BOM)

가이드에는 인코딩 타입이 UTF-8 이라고만 나와있지만, 샘플 데이터가 UTF-8(BOM) 으로 나와있으니 맞춰주자.
엑셀로는 csv 파일 인코딩을 시도해도 잘 안돼서
1. 업로드할 csv 파일 노트패드로 열기
2. 샘플 데이터를 vscode로 열기
3. 1의 내용을 2에 복붙
4. 저장
💥 csv 파일은 Ojbect Storage 에 업로드
로컬로 있는 csv 파일을 업로드하니 '학습생성 API' 호출이 발생하여
네이버클라우드의 Oject Storage 에 올려서 경로를 참조한다.
# -*- coding: utf-8 -*-
import base64
import hashlib
import hmac
import requests
import time
class CreateTaskExecutor:
def __init__(self, host, uri, method, iam_access_key, secret_key, request_id):
self._host = host
self._uri = uri
self._method = method
self._api_gw_time = str(int(time.time() * 1000))
self._iam_access_key = iam_access_key
self._secret_key = secret_key
self._request_id = request_id
def _make_signature(self):
secret_key = bytes(self._secret_key, 'UTF-8')
message = self._method + " " + self._uri + "\n" + self._api_gw_time + "\n" + self._iam_access_key
message = bytes(message, 'UTF-8')
signing_key = base64.b64encode(hmac.new(secret_key, message, digestmod=hashlib.sha256).digest())
return signing_key
def _send_request(self, create_request):
headers = {
'X-NCP-APIGW-TIMESTAMP': self._api_gw_time,
'X-NCP-IAM-ACCESS-KEY': self.Python
_iam_access_key,
'X-NCP-APIGW-SIGNATURE-V2': self._make_signature(),
'X-NCP-CLOVASTUDIO-REQUEST-ID': self._request_id
}
result = requests.post(self._host + self._uri, json=create_request, headers=headers).json()
return result
def execute(self, create_request):
res = self._send_request(create_request)
if 'status' in res and res['status']['code'] == '20000':
return res['result']
else:
return res
if __name__ == '__main__':
completion_executor = CreateTaskExecutor(
host='https://clovastudio.apigw.ntruss.com',
uri='/tuning/v2/tasks',
method='POST',
iam_access_key='',
secret_key='',
request_id='1'
)
request_data = {'name': 'generation_task',
'model': 'HCX-003',
'tuningType': 'PEFT',
'taskType': 'GENERATION',
'trainEpochs': '8',
'learningRate': '1e-5f',
'trainingDatasetBucket': 'bucket_name',
'trainingDatasetFilePath': 'modified_tuning_data_test.csv',
'trainingDatasetAccessKey': '',
'trainingDatasetSecretKey': ''
}
response_text = completion_executor.execute(request_data)
print(request_data)
print(response_text)
- trainingDatasetBucket = 버킷 이름
- trainingDatasetFilePath = 파일이 있는 경로 이름 (버킷 이름 생략 - 가이드에 애매하게 나와있으니 주의한다.)
C. 개발 & 배포
- 프론트 : streamlit
- 백 : fastapi
- 배포 : Docker + Koyeb
개발자분께서 빠르게 개발해주셨다.
참고로 배포로는 Koyeb을 처음 써봤는데 (Heroku 언제 유료 된거?),
- 직관적인 UI
- Docker Hub, Github 레포랑 직접 연결 가능
이라는 장점이 있었다
4. 후기
A. 프롬프트 작성하는 법을 조금은 알게된 것 같다.
작년에는 [한 문장짜리 지시문 + 무작정 길고 많은 예시] 조합으로 프롬프트를 썼다. HyperClova 프롬프트 작성 노하우 자료가 많이 없기도 했지만, 다양하고 실험적인 시도를 많이 해보지 않았다.
이번에는 스터디원들에게 공개된 프롬프트 작성 가이드 유튜브의 도움을 받아
페르소나 지정, output 형식 지정 등 다양한 지시문을 써봤다. 지시문만 잘 작성해도 활용도가 배는 높아진다. 프롬프트 쓰는 데에 솔직히 정답은 없는 것 같지만! 나만의 방법을 찾아가고 싶다.
B. 향상된 하이퍼클로바 모델 성능에 감격함
작년에 애먹었던 부분 : 갑자기 동화 전개 한문장만에 공주 죽이고 이혼함 & 멸망 엔딩
AI한테 인간과 같은 발화 성능을 기대하는 것은 무리지만, 내가 원하는 생성 결과가 도저히 안나올 때가 가장 답답했던 것 같다.
이번에 HCX-003 엔진으로 똑같은 프롬프트를 써서 비교해봤는데, 훨씬 자연스러운 결과가 나와서 만족. (한 학기만 늦게 졸업할걸)
인어공주는 배 갑판에 서 있는 왕자님을 본 순간 숨을 쉴 수가 없었어요.
-> 다음에 올 문장
기존 HyperClova LK-D2 엔진
: 왕자는 폭풍우 치는 밤 파도에 휩쓸려 목숨을 잃었어요. 인어공주는 왕자를 살리기 위해 목소리를 바치고 인간 다리를 얻었지요.
HyperClova X HCX-003 엔진
왕자님께 첫눈에 반해버린 인어공주는 어떻게든 왕자님과 가까워지고 싶었어요. 그래서 인어공주는 용기를 내어 배 근처로 다가갔어요. 마침 배가 폭풍우를 만나 부서졌고 정신을 잃은 왕자님을 구한 인어공주는 왕자님을 바닷가로 데려갔어요.
=====================================================================================
어느 날 호기심 많은 아기 도깨비는 모두가 잠든 틈을 타 몰래 마을을 빠져나왔어요. 아기 도깨비가 처음 보는 물고기와 해파리, 신기한 해조류들이 넘쳐났어요. 그는 더욱 먼 곳으로 모험을 떠났어요. 그러다가 그는 신비로운 해저 동굴을 발견했어요.
-> 다음에 올 문장
기존 HyperClova LK-D2 엔진
그곳엔 인어 할머니가 앉아있었어요. 그녀는 깊은 심해 속에서만 자라는 해초를 먹고 산다고 했어요.
HyperClova X HCX-003 엔진
아기 도깨비는 동굴 안으로 들어가 보았어요. 그 안에는 반짝반짝 빛나는 보석들이 가득했고, 처음 보는 거대한 문이 있었어요. 아기 도깨비는 조심스럽게 문을 열어 보았답니다.
C. 그 외
내 분야의 공부 뿐만 아니라 신기술에 대한 트렌드 캐치를 꾸준히 해야겠다는 생각. 다른 팀 스터디원들을 보니 대학교 2학년부터 팀장, 이사님까지 다양한 직책과 직군의 사람들이 모였었다. 우리 팀은 R&R이 확실히 나뉘어져 있었고, 참여도가 다들 높아서 끝까지 재미있게 완주할 수 있었다. 미팅도 매주 자정까지 함. 협업 경험 +1 됐다.
다음에는 비슷한 주제로 해커톤도 나가보고 싶다. 끝!
'NCloud' 카테고리의 다른 글
| [NCloud] 2024 네이버클라우드 마스터데이 후기 (0) | 2024.07.05 |
|---|---|
| [NCloud] Cloud Insight 로 만드는 메일 반송률 모니터링 서비스 (1) | 2024.03.08 |

